来源 | 新智元
编辑| LRS
如果说过去几年是什么在支撑着大规模模型的发展,那一定是Transformer了!
基于Transformer,大量模型在各个领域犹如雨后春笋般不断涌现,每个模型都有不同的架构,不同的细节,以及一个不容易解释的名字。
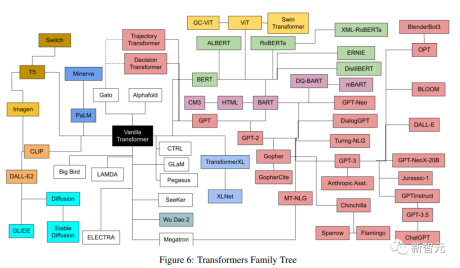
最近有作者对近几年发布的所有流行的Transformer模型进行了一次全面的分类和索引,尽可能提供一个全面但简单的目录(catalog),文中包括对Transformer创新的简介,以及发展脉络梳理。
论文链接:
https://arxiv.org/pdf/2302.07730.pdf
图灵奖得主Yann LeCun表示认可。
文章作者Xavier (Xavi) Amatriain于2005年博士毕业于西班牙庞培法布拉大学,目前是LinkedIn工程部副总裁,主要负责产品人工智能战略。
什么是Transformer?
Transformer是一类深度学习模型,具有一些独特的架构特征,最早出现在谷歌研究人员于2017年发表的著名的「Attention is All you Need」论文中,该论文在短短5年内积累了惊人的38000次引用。
Transformer架构也属于编码器-解码器模型(encoder-decoder),只不过在此之前的模型,注意力只是其中的机制之一,大多都是基于LSTM(长短时记忆)和其他RNN(循环神经网络)的变体。
提出Transformer的这篇论文的一个关键见解如标题所说,注意力机制可以作为推导输入和输出之间依赖关系的唯一机制,这篇论文并不打算深入研究Transformer架构的所有细节,感兴趣的朋友可以搜索「The Illustrated Transformer」博客。
博客链接:
https://jalammar.github.io/illustrated-transformer/
下面只简要地描述最重要的一些组件。
编码器-解码器架构一个通用的编码器/解码器架构由两个模型组成,编码器接受输入并将其编码为一个固定长度的向量;解码器接收该向量并将其解码为输出序列。